NAT Overview
文章目录
1. What is NAT?
1.1 NAT(Level 4)
NAT(Network address translation)即网络地址转换,工作在OSI模型的三层或四层(PNAT),用于修改IP数据包中的IP地址和端口。当在专用网内部的一些主机本来已经分配到了local ip地址,但又想和Internet的主机通信时,可使用NAT方法。
从NAT的映射方式来看,NAT可以分为Basic NAT和PNAT:
- Basic NAT,只转化IP,IP不复用,不映射端口。
- PNAT,除了转化IP,还复用IP,做端口映射,可以用于多个内部地址映射到少量(甚至一个)外部地址。
从NAT的生命周期来看,可以分为静态NAT和动态NAT:
- 静态NAT,将内部网络中的每个主机都永久映射成外部网络中的某个地址。
- 动态NAT,在外部网络中定义了一个或多个合法地址池,采用动态分配的方法将内部网络映射为外网网络。会话存在过期时间,过期后自动回收。
从NAT的形态上来看,可以分为锥型NAT、对称型NAT。
- 锥型NAT,锥形NAT只与源地址、源端口有关,只要源地址和源端口不变,都会分配同一个外网地址和端口。因此外网主机可以通过访问映射后的公网地址和端口,实现访问位于内网的主机设备功能。
- 对称NAT,从同一个内网IP和端口发送到同一个目的IP和端口的请求都会被映射到同一个外网IP和端口。但四元组(SIP,Sport, DIP, Dport)只要有一个发生变化都会使用不同的映射。
锥型NAT的通信双方是对等的,外网主机不管是换IP还是端口,感知到的都是对端的同一个IP和端口在提供某个特定服务,而对称型NAT违反了协议双方对等的原则,外网主机是无法主动访问内网主机的,换个外网地址或端口,NAT后的地址和端口就会变化。对称型NAT下,外网主机主动发起tcp连接,源端口是随机的(对于内网的NAT来说,即目的端口是不固定的),那么对称型NAT分配的端口也是随机的,当然这个随机端口也无法被NAT回内网。
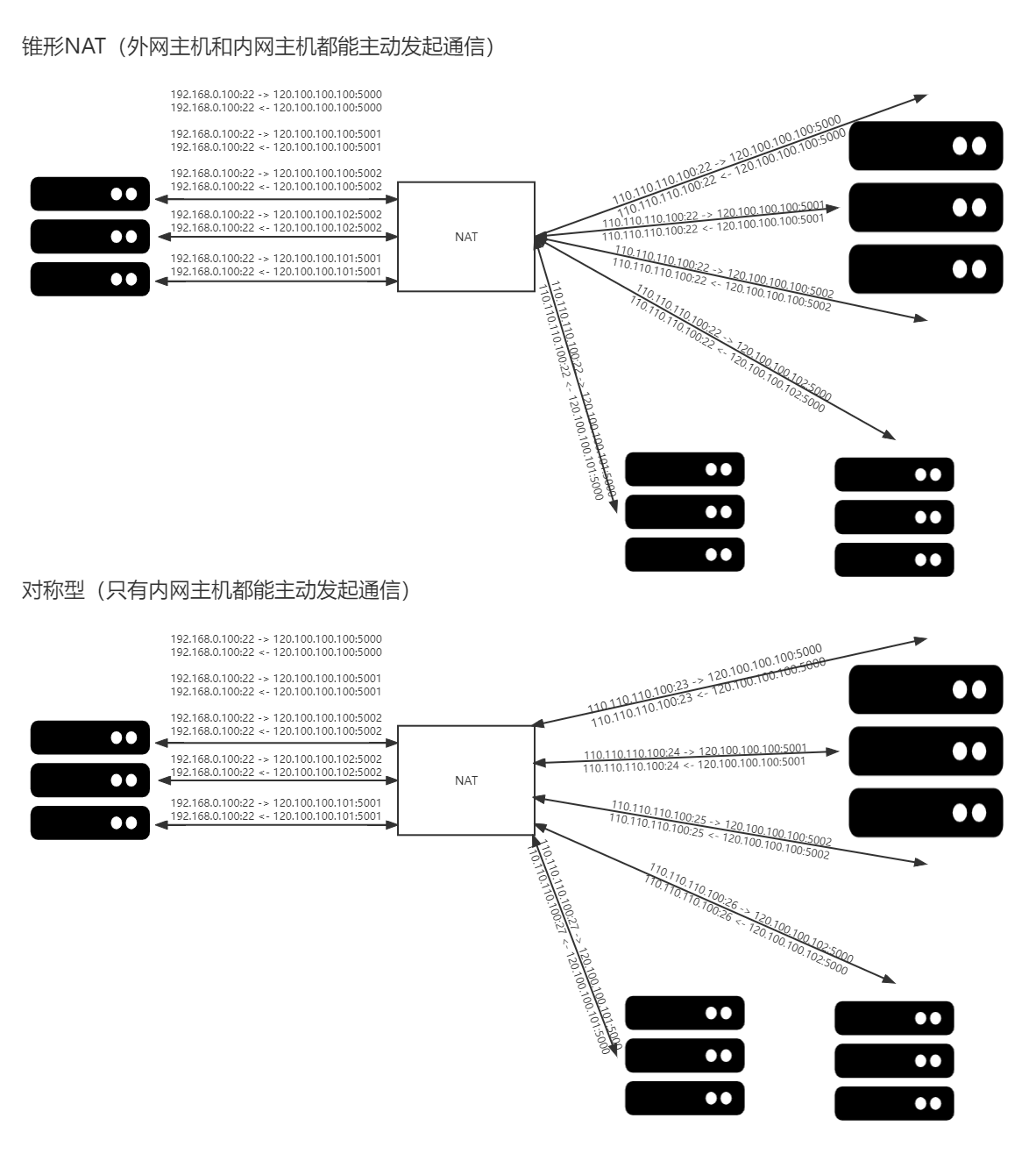
锥型NAT有两种特殊形态,即地址受限型NAT和端口受限型NAT。地址受限型NAT校验目的IP(外网的IP),因此地址受限型NAT不能主动连接内网中的主机地址,连接必须由内网地址发起。端口受限型校验目的端口和ip,地址受限型NAT只有内网主机与之通讯后,才可以进行通讯,不用担心端口号是否与内网请求的端口相同,但是端口受限型NAT也增加了端口限制。比如内网使用ip1:port1访问外网ip2:port2,地址受限型可以使用ip2:port3访问ip1:port1,但是端口受限型只能使用ip2:port2访问ip1:port1。
| NAT类型 | 说明 |
|---|---|
| 全锥型NAT | 任何公网主机都可与之通讯。双方都可以主动发起。 |
| 地址受限锥型NAT | 只有内网主动连接的公网主机可与之通讯,必须内网主机发起。且此公网主机可通过任意端口与内网主机通讯。 |
| 端口受限锥型NAT | 只有内网主动连接的公网主机的连接可与之通讯,必须内网主机发起。且此公网只能通过固定的端口与之进行通讯。 |
| 对称型NAT | 根据四元组创建NAT映射,四元组中的任何一项发生变化均导致NAT映射的更换。此形状双方一对一映射,因此被称之为对称NAT |
1.2 NAT(Level 7)
普通NAT实现了对UDP或TCP报文头中的的IP地址及端口转换功能,但对应用层数据载荷中的字段无能为力,在许多应用层协议中,比如多媒体协议(H.323、SIP等)、FTP、SQLNET等,TCP/UDP载荷中带有地址或者端口信息,这些内容不能被NAT进行有效的转换,就可能导致问题。而NAT ALG(Application Level Gateway,应用层网关)技术能对多通道协议进行应用层报文信息的解析和地址转换,将载荷中需要进行地址转换的IP地址和端口或者需特殊处理的字段进行相应的转换和处理,从而保证应用层通信的正确性。ALG需要识别并适配每一种应用协议,不同应用协议的载荷中IP地址和端口的位置不同,因此具有很大的局限性,幸运的是ALG支持了我们常用的大多数协议。
2. Why we need NAT and why we hate NAT?
2.1 advantage
- 多个内网主机共享公网IP,节省IP资源
- 作为内网流量统一出口,共享带宽
- 隐藏内网主机真实地址,避免直接暴露,可以抵挡port scan之类的攻击
- 工作在NAT模式下的lvs四层负载均衡
2.2 weakness
- NAT下的网络被分为外网和内网两部分,以网关的形式作为私网到公网的路由出口,双向流量都要经过NAT设备,容易成为性能瓶颈
- 由于NAT将内部网络信息进行了隐藏和转换,NAT下的设备无法进行对等网络传输(需要穿透NAT)
- NAT不能实现对通信双方的全透明,因为上层协议可能在传输的数据包中携带ip和port信息(需要七层ALG)
- 应用层需保持UDP会话连接。由于NAT资源有限,所以UDP的会话会很快被回收(以便端口重用)。由于UDP是无连接的,因此UDP层应用需要在无数据传输、但需要保持连接时通过heartbeat的方式保持会话不过期。
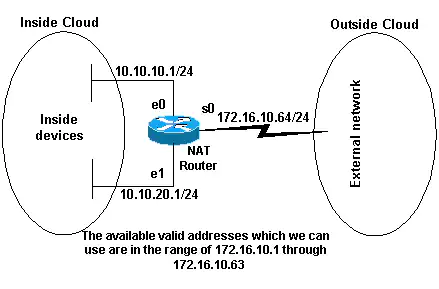
3. How to NAT in router?
以下配置了子网10.10.10.0/24的前32个地址和子网10.10.20.0/24的前32个地址可以通过NAT访问外网,内部网络中可能有其他设备具有其他地址,但这些地址不会被转换。
1 | interface ethernet 0 |
4. How to NAT in Linux?
在物理网络中,NAT功能一般由路由器或防火墙之类的设备来承载,而Iptables则是linux提供的用户态命令行工具(实际是工作的是在内核态的netfilter),可以通过在nat表中增加规则,实现在PREROUTING和POSTROUTING链上的DNAT和SNAT功能。要使用Linux提供的nat功能,首先需要确认主机支持转发,可通过以下方式确认:
1 | cat /proc/sys/net/ipv4/ip_forward |
回显结果:1为开启,0为关闭,默认为0。
如未打开,可通过修改
/etc/sysctl.conf文件,配置net.ipv4.ip_forward = 1后执行sysctl -p /etc/sysctl.conf启用转发功能。
4.1 SNAT
SNAT是为了让内网主机访问外网主机,将出方向报文的源地址进行替换,因此可以在POSTROUTING链上添加如下规则。
1 | 将192.168.1.0/24网段的源地址替换为100.32.1.100 |
4.2 DNAT
DNAT是为了让外网主机访问内网主机,将入方向报文的目的地址进行替换,因此可以在PREROUTING链上添加如下规则。
1 | 全端口映射 |
iptables提供的NAT功能并不会对范围大小、端口冲突功能进行检查。iptables的工作原理为在一条链上从前到后匹配,前面的规则会覆盖后面的规则。
4.3 Conntrack
上面我们提到了使用iptables实现SNAT功能,而SNAT存在多个内网主机通过分配端口复用同一个公网IP的情况,因此需要有个状态保持机制来记录这个会话,这个功能模块就是Conntrack。
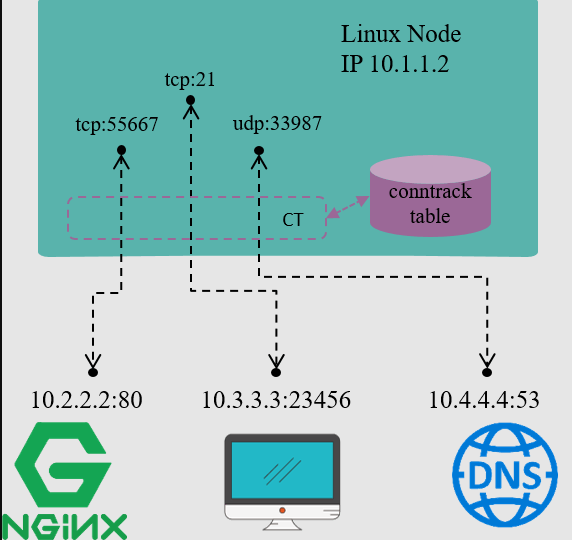
连接跟踪(Conntrack),顾名思义,就是跟踪(并记录)连接的状态。例如,上图是一台IP地址为10.1.1.2的Linux机器,我们能看到这台机器上有三条连接:
- 内部访问外部HTTP服务的连接(目的端口 80)
- 外部访问内部FTP服务的连接(目的端口 21)
- 内部访问外部DNS 服务的连接(目的端口 53)
连接跟踪所做的事情就是发现并跟踪这些连接的状态,具体包括:
- 从数据包中提取元组(tuple)信息,辨别数据流(flow)和对应的连接(connection)
- 为所有连接维护一个状态数据库(conntrack table),例如连接的创建时间、发送包数、发送字节数等等
- 回收过期的连接(GC)
- 为更上层的功能(例如 NAT)提供服务
Conntrack在Linux中是通过NetFilter实现,Netfilter 是Linux内核中一个对数据包进行控制、修改和过滤(manipulation and filtering)的框架。它在内核协议栈中设置了若干hook点,以此对数据包进行拦截、过滤或其他处理。说地更直白一些,hook机制就是在数据包的必经之路上设置若干检测点,所有到达这些检测点的包都必须接受检测,根据检测的结果决定:
- 放行:不对包进行任何修改,退出检测逻辑,继续后面正常的包处理
- 修改:修改IP地址或端口进行NAT,然后将包放回正常的包处理逻辑
- 丢弃:安全策略或防火墙功能
连接跟踪模块只是完成连接信息的采集和录入功能,并不会修改或丢弃数据包,后者是其他模块(例如 NAT)基于
Netfilter hook完成的。
5. How to NAT in cloud?
“NAT网关”作为云服务的一种,面向公有云客户服务,工作在overlay网络,其一般基于通用服务器(一般为Linux服务器)实现。在How to NAT in Linux一节中,我们已经知道,可以通过netfilter来实现,但这种方式只能靠单机工作,存在着性能瓶颈和单点故障的问题。为了提高性能和可靠性,我们可以从两方面入手,分别是scale up和scale out。同时,公有云服务面向了很多客户,因此云上NAT的功能对我们还有一个特殊的要求,实现多租户配置隔离。
5.1 Scale up
5.1.1 Better Hardware
Scale up最简单的方式就是增强硬件,这种方式只能在一定程度上提高性能,但受限于硬件能力,还是存在性能上限,且存在单点故障的缺陷。
- bigger cpu core
- greater bandwidth NIC
5.1.2 Architecture Refactor
Scale up的另外一种方式就是重构,通过这种方式我们可以提高硬件的利用效率,从而增强我们的转发性能。
网络设备(路由器、交换机等)需要在瞬间进行大量的报文收发,因此在传统的网络设备上,往往能够看到专门的NP(Network Process)处理器,有的用FPGA,有的用ASIC。这些专用器件通过内置的硬件电路(或通过编程形成的硬件电路)高效转发报文,只有需要对报文进行深度处理的时候才需要CPU干涉。
但在公有云、NFV等应用场景下,基础设施以CPU为运算核心,往往不具备专用的NP处理器,操作系统也以通用Linux为主,软件包的处理通常会经过用户态和内核态之间的切换。在虚拟化环境下,路径则会更长,需要分别经过HostOs和GuestOs两层用户态和内核态的切换。基于Linux服务器的报文转发,主要存在以下问题:
- 传统的收发报文方式都必须采用硬中断来做通讯,每次硬中断大约消耗100微秒,这还不算因为终止上下文所带来的Cache Miss。
- 数据必须从内核态用户态之间切换拷贝带来大量CPU消耗,全局锁竞争。
- 收发包都有系统调用的开销。
- 内核工作在多核上,为可全局一致,即使采用Lock Free,也避免不了锁总线、内存屏障带来的性能损耗。
- 从网卡到业务进程,经过的路径太长,有些其实未必要的,例如netfilter框架,这些都带来一定的消耗,而且容易Cache Miss。
为了提升在通用服务器的数据包处理效能,Intel推出了服务于IA(Intel Architecture)系统的DPDK(Data Plane Development Kit)技术。DPDK应用程序运行在操作系统的User Space,利用自身提供的数据面库进行收发包处理,绕过了Linux内核态协议栈,以提升报文处理效率。DPDK的UIO驱动屏蔽了硬件发出中断,然后在用户态采用主动轮询的方式,这种模式被称为PMD(Poll Mode Driver)。
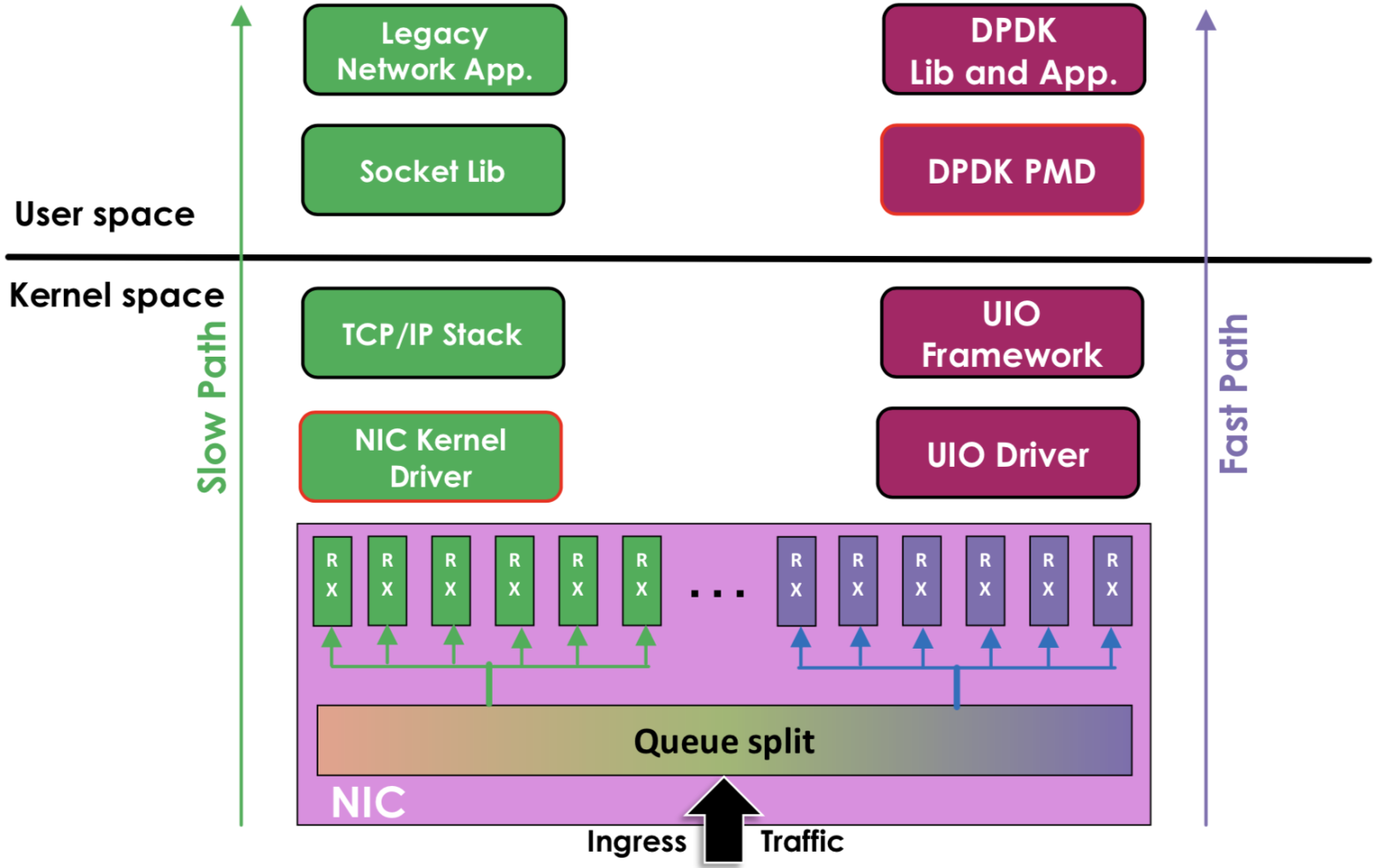
左边是原来的方式数据从 网卡 -> 驱动 -> 协议栈 -> Socket接口 -> 业务
右边是DPDK的方式,基于UIO(Userspace I/O)旁路数据。数据从 网卡 -> DPDK轮询模式-> DPDK基础库 -> 业务
用户态的好处是易用开发和维护,灵活性好。并且Crash也不影响内核运行,鲁棒性强。
5.2 Scale out
Scale up的本质还是在提高单机的性能,存在理论性能上限和单点故障问题。云计算的本质就是池化,实现网关的动态弹性扩容才是根本解决方案。通过Scale out的方式可以无限扩容,提高性能,且集群化后,可以避免单点故障,提高可靠性。
由于NAT网关是有状态的网关,因此无法直接横向扩容,每个节点不能单独管理会话,否则很容易出现冲突。因此Aws提出了一种三层架构形态的网络,即HyperPlane。HyperPlane将网络分为以下三种类型:
- TOP: 无状态的转发,一旦网络连接建立后,转发只会在TOP层完成,可以无限横向扩容。
- FLOW MASTER:用来记录网络连接信息,FLOW MASTER是无状态通用的。
- DECIDER:具体实现网络功能逻辑,不同网关实现不同。对于NAT来说,就是实现SNAT和DNAT规则的转换。
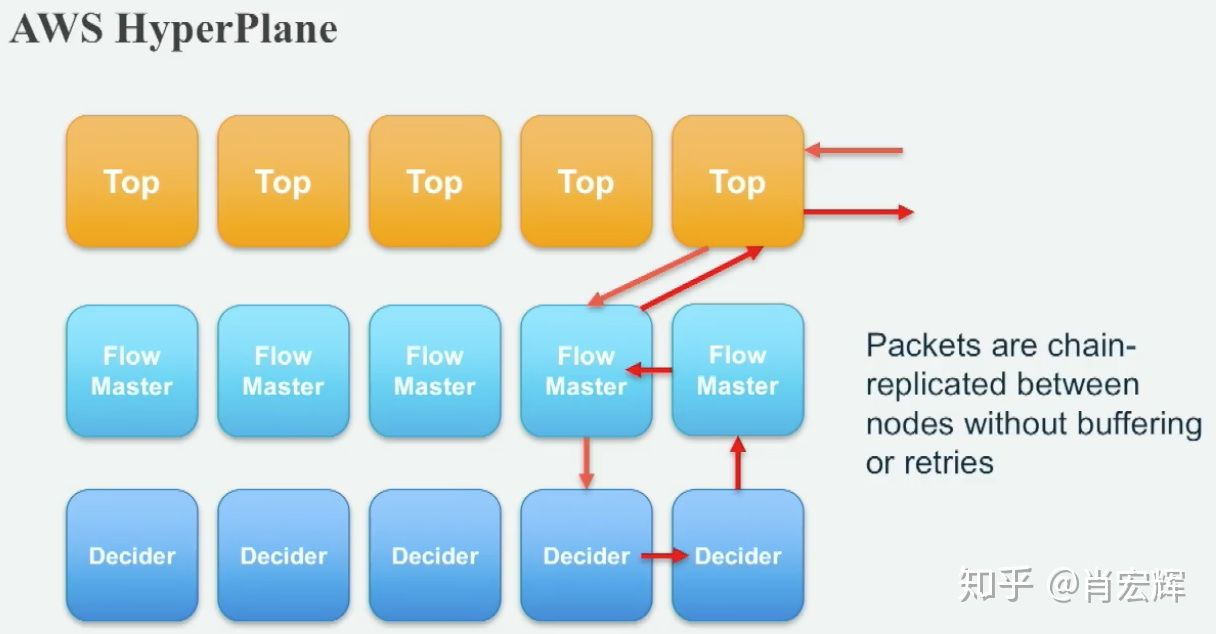
这里的每个节点都使用的是池化的ECS,具有很强的弹性扩缩能力。
- TOP节点成为了无状态的网关,可以理论无限扩容,大大提高了整个网关平台的转发能力
- Flow Master对于所有网关形态来说,不同的五元组都可以交由不同的Flow Master管理链接状态。FLow Master可以做到横向扩容,基于五元组hash,没有会话状态可以向Decider申请。
- Decider不同与Flow Master,对于有状态的网关,不同的实例可以由不同的Decider管理,但同一个实例必须由同一个Decider管理。Decider横向扩容需要考虑hash策略变化带来的会话同步问题。
- Flow Master和Decider存有会话信息,通过绕行两个节点形成主备,消除单点故障问题。
5.3 Tenant Isolation
这个就比较简单,云上数据包一般都会使用VXLAN协议进行过传递,通过对VXLAN报文中的VNI进行解析,将SNAT规则和DNAT规则与VNI进行绑定,即可实现不同租户之间的规则隔离。
6. NAT Traversal
目前运营商提供的光猫上网服务和绝大多数的路由器都是锥型NAT,锥型NAT可以实现NAT穿越,从而实现P2P。
6.1 锥型NAT
处于不同内网的主机A和主机B,各自先连接服务器,从而在各自NAT设备上打开了一个“孔”,服务器收到主机A和主机B的连接后,知道A与B的公网地址和NAT分配给它们的端口号,然后把这些NAT地址与端口号告诉A与B,由于在锥型NAT的特点,A和B给服务器所打开的“孔”,能给别的任何的主机使用。故A与B可连接对方的公网地址和端口直接进行通信。服务器在这里充当“介绍人”,告诉A与B对方的地址和端口号。
6.2 地址受限锥型NAT
A和B还是要先连接服务器,服务器发送A和B的地址和端口信息给A和B,但由于受限制锥形NAT的特点,他们所打开的“孔”,只能与服务器通信。要使他们可以直接通信,解决办法如下:
假如主机A开始发送一个UDP信息到主机B的公网地址上,与此同时,它又通过服务器中转发送了一个邀请信息给主机B,请求主机B也给主机A发送一个UDP信息到主机A的公网地址上。这时主机A向主机B的公网IP发送的信息导致NAT A打开一个处于主机A的和主机B之间的会话,与此同时,NAT B也打开了一个处于主机B和主机A的会话。一旦这个新的UDP会话各自向对方打开了,主机A和主机B之间就可以直接通信了。
6.3 端口受限锥型( Port Restricted Cone)NAT
6.4 对称型(Symmetric)NAT
对称型NAT,对于不同的四元组,它都会分配不同的端口号,所以进行打孔比较困难,但也可以进行端口预测打孔,不过不能保证成功。通常,对称NAT分配端口有两种策略,一种是按顺序增加,一种是随机分配。如果这里对称NAT使用顺序增加策略,那么,ClientB将两次被分配的外网地址和端口发送给Server后,Server就可以通知ClientA在这个端口范围内猜测刚才ClientB发送给它的socket中被NAT映射后的外网地址和端口,ClientA很有可能在孔有效期内成功猜测到端口号,从而和ClientB成功通信。
此外对称型NAT可以使用第三方服务器作为中继者,ClientA和ClientB之间的流量都通过中继服务器C中转,但是中继服务器容易成为性能瓶颈。
以上的NAT穿透,都是对PNAT来进行穿透,主要是针对UDP协议,语音视频通信是用UDP传输的。Basic NAT不修改经过的数据包的端口号,它们可以看作是完全锥形NAT的精简版本,即Basic NAT也可以被穿透。NAT设备将在一定时间后关闭UDP的一个映射,所以为了保持与服务器能够一直通信,服务器或客户端必须要周期性地发送UDP包,保持映射不被关闭。
以上的NAT穿越,都是基于UDP的NAT穿越。UDP的socket允许多个socket绑定到同一个本地端口,而TCP的socket则不允许。想象一下,如果Client A使用IPA:2000端口和服务器通信,那么Client主机已经使用IPA:2000这个socket和服务器建立了一条TCP流,自然也无法再使用IPA:2000端口和client B建立一条TCP流,而UDP是可以做到的。
6.5 NAT-DDNS穿透
NAT-DDNS是将用户的动态IP地址映射到一个固定的域名上,用户每次连接网络的时候客户端程序就会通过信息传递把该主机的动态IP地址传送给位于服务商主机上的服务器程序,服务项目器程序负责提供DNS服务并实现动态域名解析。DDNS的主要作用就是捕获用户每次变化的IP地址,然后将其与域名相对应,这样其他上网用户就可以通过域名来与用户交流了。可以通过NAT-DDNS穿透来实现家用主机面向互联网提供服务。
6.6 TCP打洞
6.6.1 套接字和TCP端口的重用
实现基于TCP协议的p2p”打洞”过程中,最主要的问题不是来自于TCP协议,而是来自于来自于应用程序的API接口。这是由于标准的伯克利(Berkeley)套接字的API是围绕着构建客户端/服务器程序而设计的,API允许TCP流套接字通过调用connect()函数来建立向外的连接,或者通过listen()和accept()函数接受来自外部的连接,但是,API不提供类似UDP那样的,同一个端口既可以向外连接,又能够接受来自外部的连接。而且更糟的是,TCP的套接字通常仅允许建立1对1的响应,即应用程序在将一个套接字绑定到本地的一个端口以后,任何试图将第二个套接字绑定到该端口的操作都会失败。
为了让TCP”打洞”能够顺利工作,我们需要使用一个本地的TCP端口来监听来自外部的TCP连接,同时建立多个向外的TCP连接。幸运的是,所有的主流操作系统都能够支持特殊的TCP套接字参数,通常叫做SO_REUSEADDR,该参数允许应用程序将多个套接字绑定到本地的一个端口(只要所有要绑定的套接字都设置了SO_REUSEADDR参数即可)。BSD系统引入了SO_REUSEPORT参数,该参数用于区分端口重用还是地址重用,在这样的系统里面,上述所有的参数必须都设置才行。
6.6.2 打开p2p的TCP流
假定客户端A希望建立与B的TCP连接。我们像通常一样假定A和B已经与公网上的已知服务器、建立了TCP连接。服务器记录下来每个连入的客户端的公网地址和端口,如同为UDP服务的时候一样。从协议层来看,TCP”打洞”与UDP”打洞”是几乎完全相同的过程。
1、客户端A使用其与服务器的连接向服务器发送请求,要求服务器协助其连接客户端B。
2、服务器将B的公网IP和端口返回给A,同时,服务器将A的公网地址和端口发送给B。
3、客户端A和B使用连接服务器的端口异步地发起向对方的公网地址和端口的TCP连接,同时监听各自的本地TCP端口是否有外部的连接。
4、A和B开始等待向外的连接是否成功,检查是否有新连接进入。如果向外的连接由于某种网络错误而失败,如:”连接被重置”或者”节点无法访问”,客户端只需要延迟一小段时间(例如延迟一秒钟),然后重新发起连接即可,延迟的时间和重复连接的次数可以由应用程序编写者来确定。A发出SYN报文到达B的NAT设备,B的NAT设备如果是全锥型NAT,则连接直接建立,否则B的NAT设备丢弃该报,此时B的SYN报文到达A端NAT设备,而A端NAT设备由于看到了A主动访问B的流,因此将SYN报文NAT后转给了A,A的listen()函数生效,连接建立成功。
6、TCP连接建立起来以后,客户端之间应该开始鉴权操作,确保目前联入的连接就是所希望的连接。如果鉴权失败,客户端将关闭连接,并且继续等待新的连接接入。客户端通常采用”先入为主”的策略,只接受第一个通过鉴权操作的客户端,然后将进入p2p通信过程不再继续等待是否有新的连接接入。
7. Other Tech
7.1 会话结构
首先定义几个概念:
- CIP,内网主机的IP
- Cport,内网主机的port
- DIP,外网主机的IP
- Dport,外网主机的port
- TIP,NAT后的IP
Tport,NAT后的port
7.1.1 完全锥型NAT
Up Key,内部四元组(CIP、Cport、Protocol)
- Down Key,外部四元组(TIP、Tport、Protocol)
- Session,Up key + Down key + Start Time + ExpireTime
上行,内网主机访问外网只要CIP、Cport不变,一定会映射到TIP、Tport;下行,外网主机访问TIP、Tport总能NAT会内网的CIp和Cport;在Key中添加protocol可以实现TCP和UDP单独管理,也可以不使用Protocol作为key字段来统一管理。
7.1.2 地址受限型NAT
- Up Key,内部四元组(CIP、Cport、Protocol)
- Down Key,外部四元组(TIP、Tport、DIP、Protocol)
- Session,Up key + Down key + Start Time + ExpireTime
上行,内网主机访问外网只要CIP、Cport不变,一定会映射到TIP、Tport;下行,外网主机以DIP为源地址,端口任意访问TIP、Tport可以NAT回内网的CIp和Cport,换个DIP则不行
7.1.3 端口受限型NAT
- Up Key,内部四元组(CIP、Cport、Protocol)
- Down Key,外部四元组(TIP、Tport、DIP、DPORT、Protocol)
- Session,Up key + Down key + Start Time + ExpireTime
上行,内网主机访问外网只要CIP、Cport不变,一定会映射到TIP、Tport;下行,外网主机以DIP为源地址、DPort访问TIP、Tport可以NAT回内网的CIp和Cport,换个DIP或DPORT都不行。
7.1.4 对称型NAT
- Up Key,内部四元组(CIP、Cport、DIP、Dport、Protocol)
- Down Key,外部四元组(TIP、Tport、DIP、Dport、Protocol)
- Session,Up key + Down key + Start Time + ExpireTime
上行,内网主机访问外网主机,只有(CIP、Cport、DIP、Dport)任意一个发生变化都会产生新会话,即分配新的TIP或TPORT;下行,外网主机只能以固定的DIP和Dport访问固定的TIP、Tport。
7.2 会话分配
这里假设TIP只有一个,实际可以配置多个,通过hash的方式随机选择一个TIP就行了,因此以下我们只讨论在一个TIP的情况下保证会话分配不冲突。
7.2.1 锥型NAT
仅需要管理TIP对应的PORT即可,TIP + PORT会固定映射为某个CIP + CPORT的逻辑。因此数据结构可以设置为:
1 | struct nat_port_key { |
7.2.2 对称型NAT
对于内网主机来说,NAT后的地址和端口并不感知,而对于外网主机来说是感知的,因此对称型NAT需要保证(TIP,Tport,DIP,Dport,Protocl)不一致即可,这五元组只有任意一个不一致,就会对应不同的DOWN Key,自然也能找到对应的Session来找到UP Key,保证可以NAT回去。所以我们只需要基于DOWN Key进行管理会话即可,其中TIP我们可以作为固定值,也就是我们要基于(DIP,Dport,Protocol)来分配Tport。可设计如下数据结构:
1 | struct nat_port_key { |
此方案存在一个缺陷,因为Tport的端口被复用了。假设以下场景,DIP1和DIP2都是提供代理的VIP,他们有同一个后端(SIP,SPORT)。由于DIP1和DIP2不同,因此有可能分配到相同Tport,此时对于后端server来说就会很迷惑,因为它看到了两条不一样的(TIP,TPORT,SIP,SPORT)流,后端服务的协议栈处理的数据流必然也是乱套的,流量就会不同。
8. Refrence
原文作者: shinerio
原文链接: https://shinerio.cc/2022/05/04/计算机网络/4W For NAT/
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议